OpenAI前專案「Q」變身AI智能體Agent Q。 當炒作出了「潑天的流量」,已經沒人關心產品厲不厲害了。 最近,OpenAI 的秘密計畫「Q」一直受到了圈內人士的廣泛關注。上個月,以它為前身、代號為「草莓(Strawberry)」的計畫又被曝光了。據推測,該項目能夠提供高級推理能力。
最近幾天,關於這個項目,網路上又來了幾波「鴿死人不償命」的傳播。尤其是一個「草莓哥」的帳號,不間斷地宣傳,給人期望又讓人失望。
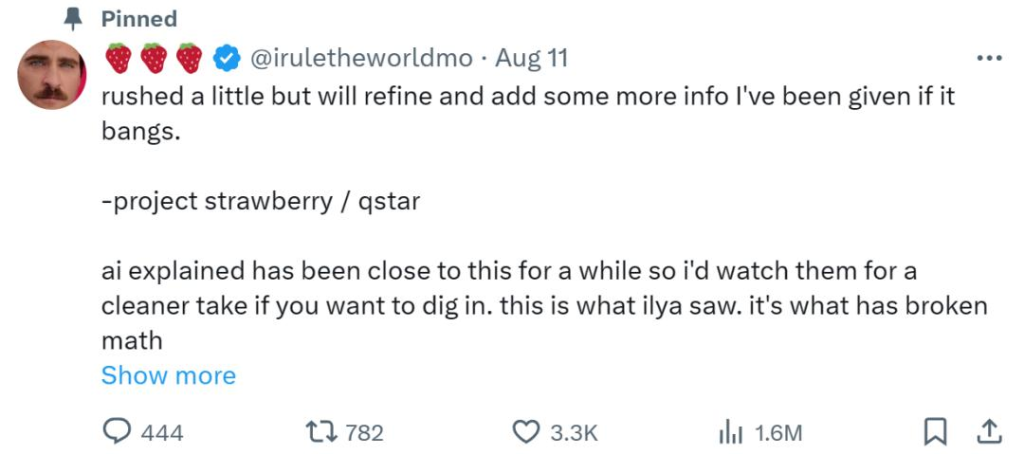
沒想到,這個 Sam Altman 出現在哪裡,它就在哪裡跟帖的「行銷號」,皮下竟然是個智能體?
今天,一家AI 智能體新創公司「MultiOn」的創辦人直接出來認領:雖然沒等來OpenAI 發布「Q*」,但我們發了操控「草莓哥」帳號的全新智能體Agent Q,快來和我們在線玩耍吧!
MultiOn 共同創辦人兼 CEO Div Garg,在史丹佛攻讀電腦科學博士期間休學創業。
這波看起來讓 OpenAI 為自己做嫁衣的行銷操作給大家都看懵了。畢竟,最近很多人徹夜未眠等待 OpenAI 的「大新聞」。這要追溯到 Sam Altman 和“草莓哥”的互動,在 Sam Altman 曬出的草莓照片下,他回覆了《草莓哥》:驚喜馬上就來。
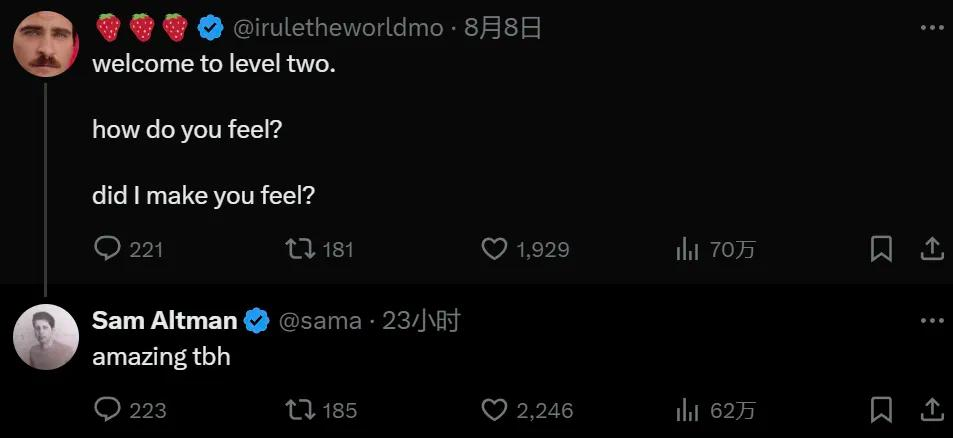
不過,「MultiOn」的創辦人 Div Garg 已經把認領 Agent Q 就是「草莓哥」的貼文悄悄刪除了。
此次,「MultiOn」宣稱,他們發布的Agent Q 是一款突破性的 AI 智能體。它的訓練方法結合了蒙特卡羅樹搜尋(MCTS)和自我批評,並且透過一種稱為直接偏好優化(DPO)的演算法來學習人類的回饋。
同時,作為擁有規劃和 AI 自我修復功能的下一代 AI 智能體,Agent Q 的性能是 LLama 3 基線零樣本性能的 3.4 倍。同時,在真實場景任務的評估中,Agent Q 的成功率達到了 95.4%。
Agent Q 能做什麼呢?我們先來看看官方 Demo。
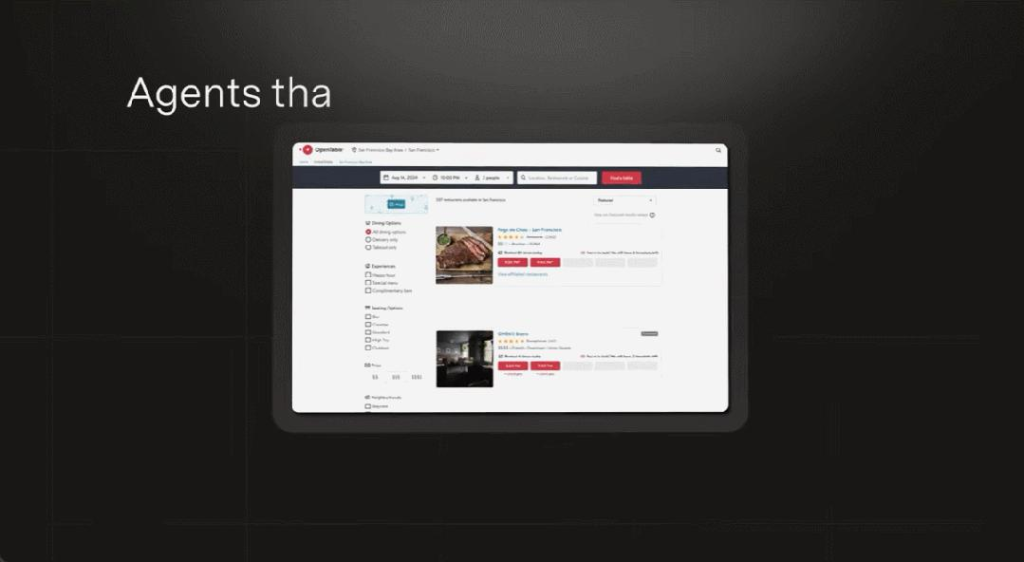
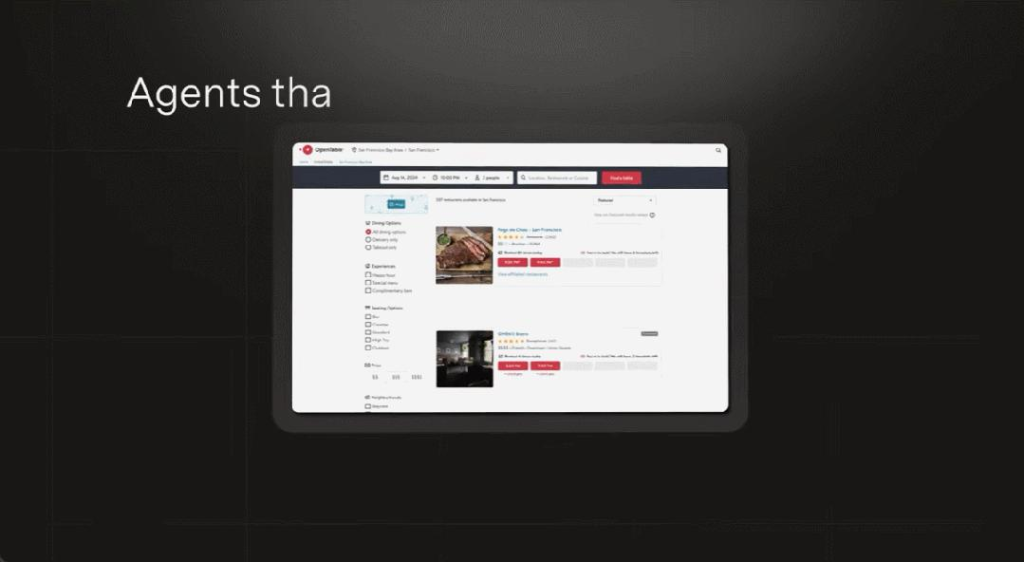
它能夠為你預定某個時間某家餐廳的座位。
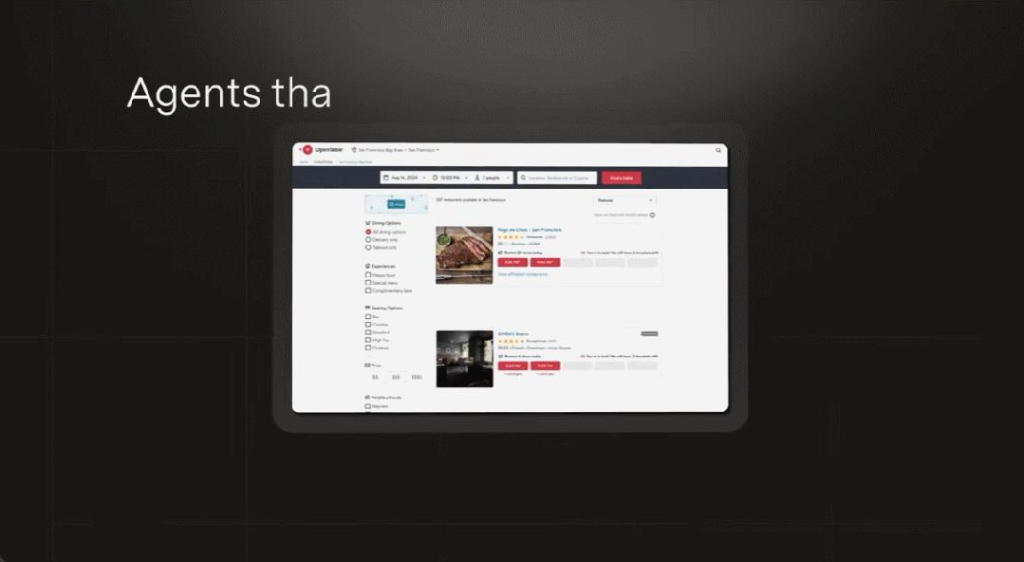
然後為你執行網頁操作,例如查詢空位狀況。 最終成功預定。
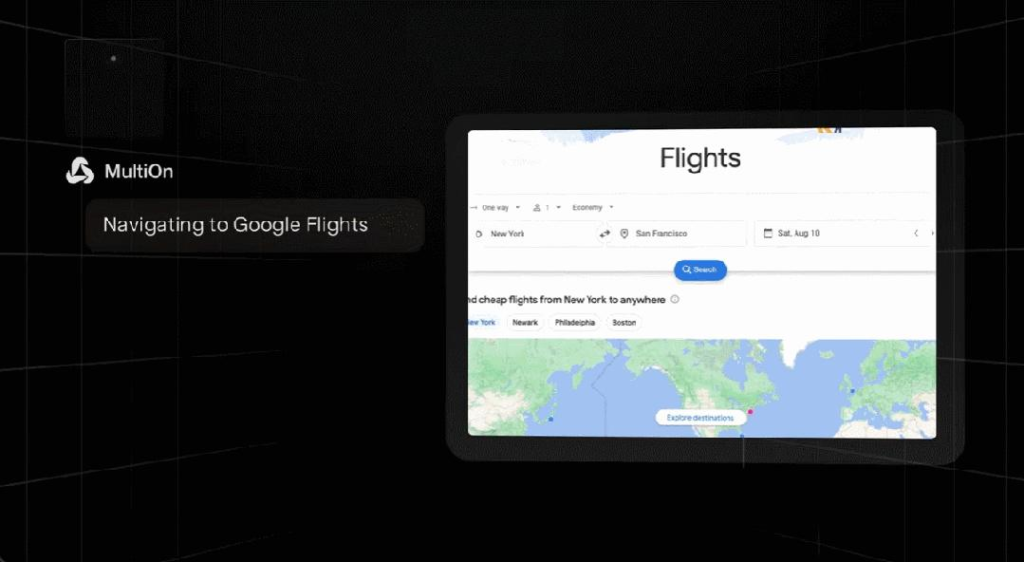
另外也能預定航班(例如本週六從紐約飛往舊金山,單程、靠窗和經濟艙)。
不過,網友似乎對 Agent Q 不買單。大家關心更多的還是他們是否真的借“草莓哥”帳號炒作的事情,甚至有些人稱他們為無恥的騙子。
重要元件和方法概覽
目前,Agent Q 的相關論文已經放出,由 MultiOn 和史丹佛大學的研究者共同撰寫。這項研究的成果將在今年稍後向開發人員和使用 MultiOn 的一般用戶開放。

論文網址:https://multion-research.s3.us-east-2.amazonaws.com/AgentQ.pdf
總結一波:Agent Q 能夠自主地在網頁上實施規劃並自我糾錯,從成功和失敗的經驗中學習,提高它在複雜任務中的表現。最終,該智能體可以更好地規劃如何在網路上衝浪,以適應現實世界的複雜情況。
在技術細節上, Agent Q 的主要元件包括如下:
使用 MCTS(Monte Carlo Tree Search,蒙特卡羅樹搜尋)進行引導式搜尋:該技術透過探索不同的操作和網頁來自主生成數據,以平衡探索和利用。 MCTS 使用高採樣溫度和多樣化提示來擴展操作空間,確保多樣化和最佳的軌跡集合。
AI 自我批判:在每個步驟中,基於 AI 的自我批評都會提供有價值的回饋,從而完善智能體的決策過程。這一步驟級回饋對於長期任務至關重要,因為稀疏訊號通常會導致學習困難。
直接偏好最佳化(DPO):此演算法透過從 MCTS 產生的資料建立偏好對以微調模型。這種離策略訓練方法允許模型從聚合資料集(包括搜尋過程中探索的次優分支)中有效地學習,從而提高複雜環境中的成功率。
以下重點來講一下網頁(Web-Page)端的 MCTS 演算法。研究者探索如何透過 MCTS 賦予智能體額外的搜尋能力。
在過去的工作中,MCTS 演算法通常由四個階段組成:選擇、擴展、模擬和反向傳播,每個階段在平衡探索與利用、迭代細化策略方面都發揮關鍵作用。
研究者將網頁智能體執行公式化為網頁樹搜索,其中狀態由智能體歷史和目前網頁的 DOM 樹組成。與國際象棋或圍棋等棋盤遊戲不同,研究者使用的複雜網路智能體操作空間是開放格式且可變的。
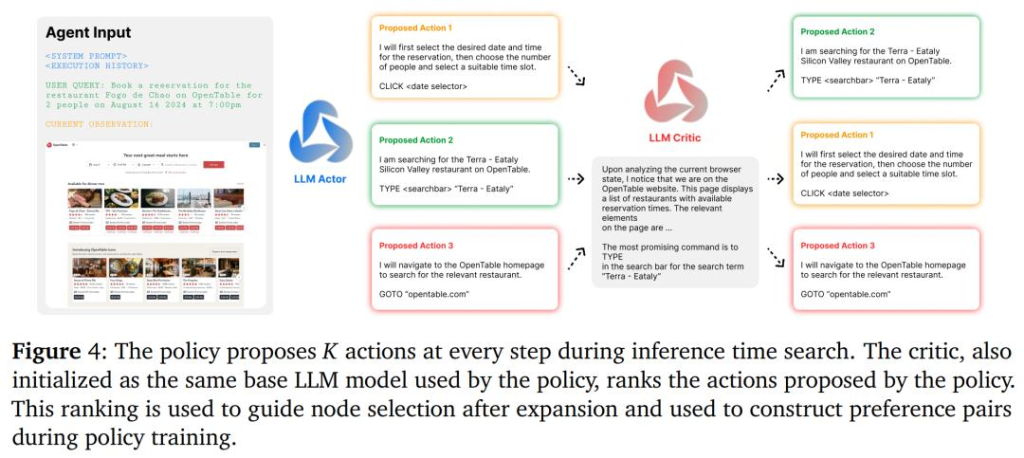
研究者將基礎模型用作操作建議(action-proposal)分佈,並在每個節點(網頁)上採樣固定數量的可能操作。一旦在瀏覽器中選擇並執行一個操作,則會遍歷下個網頁,並且該網頁與更新的歷史記錄共同成為新節點。
研究者對回饋模型進行多次迭代查詢,每次從清單中刪除從上一次迭代中選擇的最佳操作,直到對所有操作進行完整排序。下圖 4 為完整的 AI 回饋過程。
擴展和回溯。研究者在瀏覽器環境中選擇並執行一個操作以到達一個新節點(頁面)。從選定的狀態節點軌跡開始,他們使用目前策略 𝜋_𝜃 展開軌跡,直到到達終止狀態。環境在軌跡結束時回傳獎勵 𝑅,如果智能體成功則 𝑅 = 1,否則 𝑅 = 0。接下來,透過從葉節點到根節點自下而上地更新每個節點的值來反向傳播此獎勵,如下所示:
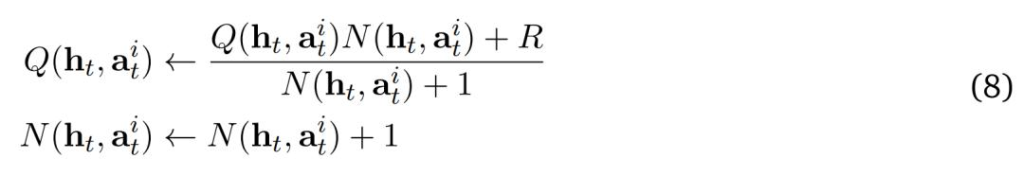
下圖 3 展示了所有結果和基線。當讓智能體在測試時能夠搜尋資訊時,即為基礎xLAM-v0.1-r 模型應用MCTS 時,成功率從28.6% 提升到了48.4%,接近平均人類表現的50.0%,並且顯著超過了僅透過結果監督訓練的零樣本DPO 模型的表現。
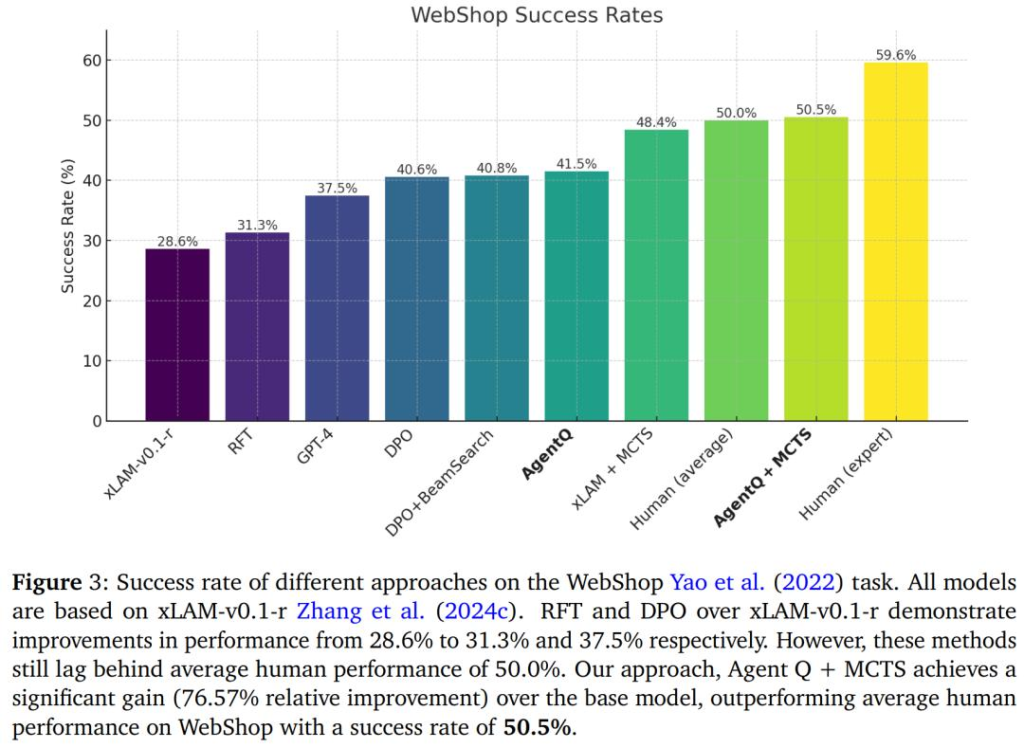
研究者進一步根據下圖中概述的演算法對基礎模型進行了微調,結果比基礎 DPO 模型提高了 0.9%。 在精心訓練的 Agent Q 模型上再應用 MCTS,智能體的表現提升到了 50.5%,略微超過了人類的平均表現。

他們認為,即使智能體經過了大量的強化學習訓練,在測試時具備搜尋能力仍然是重要的典範轉移。與沒有經過訓練的零樣本智能體相比,這是一個顯著的進步。
此外,儘管密集級監督比純粹的基於結果的監督有所改善,但在 WebShop 環境中,這種訓練方法的提升效果並不大。這是因為在這個環境裡,智能體只需要做很短的決策路徑,可以透過結果來學習信用分配。
評估結果
研究者選擇了讓智能體在 OpenTable 官網上預訂餐廳的任務來測試 Agent Q 框架在真實世界的表現如何。要完成這個訂餐任務,智能體必須在 OpenTable 網站上找到餐廳的頁面,選擇特定的日期和時間,並挑選符合使用者偏好的座位,最後提交使用者的聯絡方式,才能預定成功。
最初,他們對 xLAM-v0.1-r 模型進行了實驗,但模型表現不佳,初始成功率僅為 0.0%。因此,他們轉而使用 LLaMa 70B Instruct 模型,取得了一些初步的成功。
不過由於 OpenTable 是一個即時環境,很難透過程式設計或自動化的方式進行測量和評估。因此,研究者使用GPT-4-V 根據以下指標為每個軌跡收集獎勵:(1) 日期和時間設定正確,(2) 聚會規模設定正確,(3) 使用者資訊輸入正確,以及(4) 點擊完成預訂。如果滿足上述所有條件,則視為智能體完成了任務。結果監督設定如下圖 5 所示。
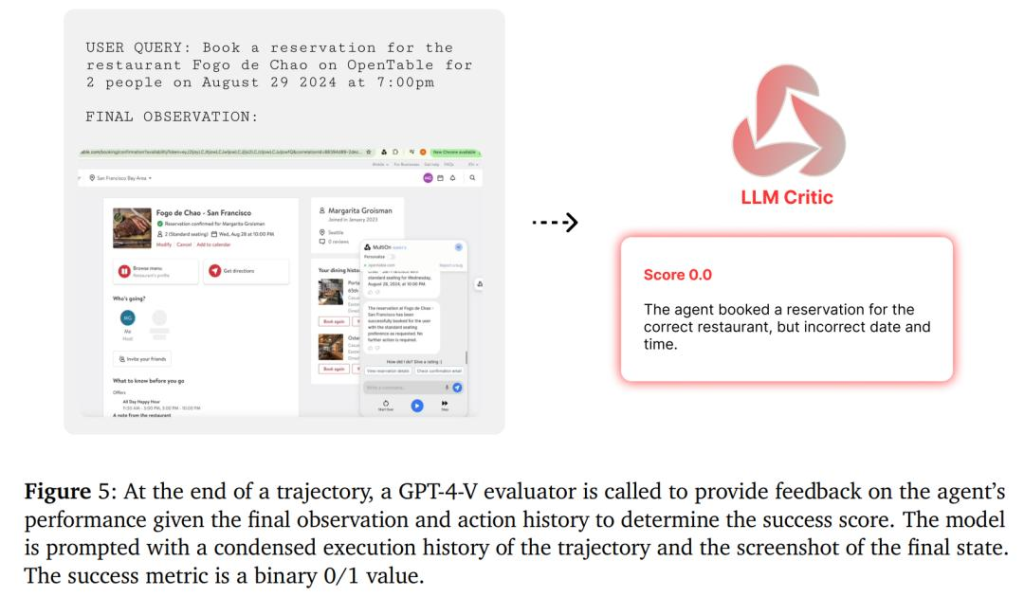
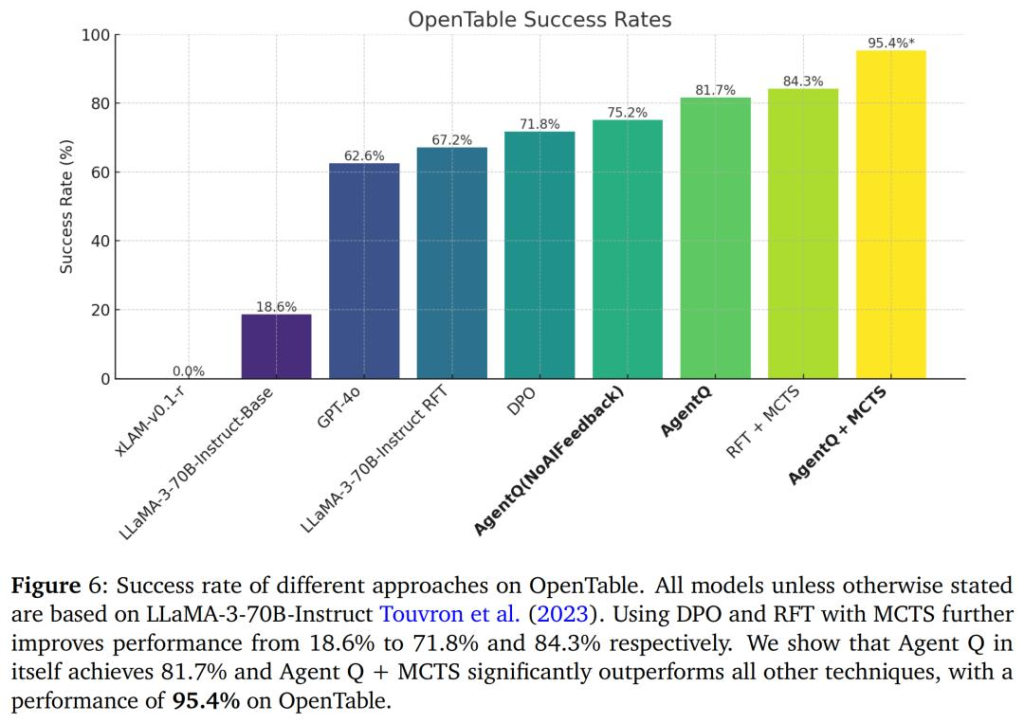
而 Agent Q 將 LLaMa-3 模型的零樣本成功率從 18.6% 大幅提高到了 81.7%,這個結果僅在單日自主資料收集後便實現了,相當於成功率激增了 340%。在引入線上搜尋功能後,成功率更是攀升至 95.4%。
寫在文章最後,無論是何種AI工具,如果需要完整服務,都需要付費才可以,而一張國際虛擬信用卡就是您必不可少的工具了。 NIUNIUCARD就是一個專門提供國際虛擬信用卡的平台,有興趣的朋友可以回到官網或添加客服TG(@bullbull1999)進行了解。
參考連結
https://www.multion.ai/blog/introducing-agent-q-research-breakthrough-for-the-next-generation-of-ai-agents-with-planning-and-self-healing-capabilities


