
這兩天,Apple Intelligence 的上線成為了最大的科技新聞之一。
雖然比起1 個多月前公佈的完整版Apple Intelligence,蘋果iOS 18.1 beta 1 中引入的Apple Intelligence 功能並不完整,Image Playground、Genmoji、優先通知、具有螢幕感知功能的Siri 和ChatGPT 整合…這些統統都還沒有。
但總的來說,蘋果還是帶來了 Writing Tools(寫作工具)、通話錄音(含轉錄)以及全新設計的 Siri。
其中,Writing Tools 支援重寫、專業化、簡略等功能,可用於聊天、發朋友圈、小紅書筆記以及文字寫作等場景;通話錄音不僅可以記錄通話,還能自動轉錄成文本,方便用戶回顧。
此外,Siri 也獲得了「升級」,可惜目前還僅限於設計,包括全新的「跑馬燈」特效以及鍵盤輸入支援。
但引人注目的是,蘋果在一篇名為《Apple Intelligence Foundation Language Models》的論文中披露,蘋果並沒有採用常見的英偉達H100 等GPU,而是選了「老對手」谷歌的TPU,訓練Apple Intelligence 的基礎模型。
圖/蘋果
用Google TPU,煉成 Apple Intelligence
眾所周知,Apple Intelligence 總共分成三層:一層是運行在蘋果設備本地的端側 AI,一層是基於「私有雲運算」技術運行在蘋果自有資料中心的雲端 AI。根據供應鏈傳出的消息,蘋果將透過大量製造 M2 Ultra 來建立自有資料中心。
另外還有一層,則是接取第三方雲端大模型,如 GPT-4o 等。
不過這就是推理端,蘋果是如何訓練出自己的 AI 模型,一直是業界關注的焦點之一。而從蘋果官方的論文來看,蘋果是在 TPUv4 和 TPUv5p 叢集的硬體上訓練了兩個基礎模型:
一個是參數規模達到3 億的設備端模型AFM-on-device,使用2048 塊TPU v5p 訓練而成,本地運行在蘋果設備上;一個是參數規模更大的伺服器端模型AFM-server,使用8192 塊TPU v4 晶片訓練,最終運行在蘋果自有資料中心。

圖/蘋果
這就奇怪了,畢竟我們都知道,英偉達 H100 等 GPU 才是目前訓練 AI 的主流選擇,甚至會有「AI 訓練只用 Nvidia GPU」的說法。
與之相對,Google的 TPU 就顯得有些「名不見經傳」。
但事實上,Google的 TPU 是專為機器學習和深度學習任務設計的加速器,能夠提供卓越的效能優勢。憑藉其高效的運算能力和低延遲的網路連接,Google的 TPU 在處理大型模型訓練任務時表現出色。
例如,TPU v4 就能提供了每個晶片高達 275 TFLOPS 的峰值算力,並透過超高速互連將 4096 個 TPUv4 晶片連接成一個大規模的 TPU 超算,從而實現算力規模的倍增。
而且不只是蘋果,其他大模型公司也採用了Google的 TPU 來訓練他們的大型模型。 Anthropic 公司的 Claude 就是一個典型的例子。
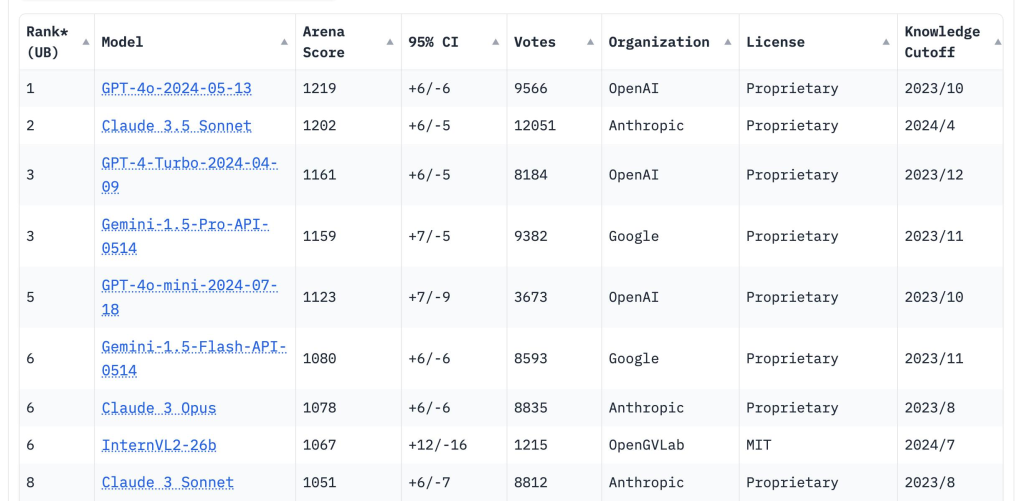
聊天機器人競技場排行,圖片/LMSYS
Claude 如今可以說是 OpenAI GPT 模型最強大的競爭對手,在 LMSYS 聊天機器人競技場上,Claude 3.5 Sonnet 與 GPT-4o 始終是「臥龍鳳雛」(褒義)。而據揭露,Anthropic 一直沒有購買英偉達 GPU 來建立超算,就是使用 Google Cloud 上 TPU 叢集來訓練和推理。
去年底,Anthropic 還官宣率先使用 Google Cloud 上的 TPU v5e 叢集來訓練 Claude。
Anthropic 的長期使用,以及 Claude 所展現的效果,都充分展現了Google TPU 在 AI 訓練中的高效性和可靠性。
此外,Google的 Gemini 也是完全依賴自研的 TPU 晶片來訓練。 Gemini 模型旨在推進自然語言處理和生成技術的前沿,其訓練過程需要處理大量的文字數據,並進行複雜的模型計算。
而 TPU 的強大運算能力和高效的分散式訓練架構,使得 Gemini 能夠在相對較短的時間內完成訓練,並在效能上取得顯著突破 。
但如果說 Gemini 尚可理解,那從 Anthropic 到蘋果為什麼選擇谷歌 TPU,而不是英偉達 GPU?
TPU 與 GPU,Google和英偉達的暗戰
在本週一舉辦的電腦圖形學頂級會議 SIGGRAPH 2024 上,英偉達創始人兼 CEO 黃仁勳透露,本周英偉達就將發送 Blackwell 架構的樣品,這是英偉達最新一代的 GPU 架構。
2024 年 3 月 18 日,英偉達 GTC 大會上發表了最新一代 GPU 架構-Blackwell,以及最新一代 B200 GPU。在效能上,B200 GPU 在 FP8 及新的 FP6 上可以達到 20 petaflops(每秒千萬億次浮點運算)的算力,使其在處理複雜 AI 模型時表現出色。
Blackwell 發布的兩個月後,Google也發布了其第六代TPU(Trillium TPU),每塊晶片在BF16 下可以提供接近1000 TFLOPS(每秒萬億次)的峰值算力,Google也將其評價為「迄今為止性能最高、最節能的TPU」。

圖片/谷歌
對比Google的 Trillium TPU,英偉達 Blackwell GPU 在高頻寬記憶體(HBM3)和 CUDA 生態系統的支援下,在高效能運算中仍有一定的優勢。在單一系統中,Blackwell可以並行連接多達 576 個 GPU,實現強大的算力和靈活的擴充性。
相較之下,Google的 Trillium TPU 則著重在大規模分散式訓練中的高效性和低延遲。 TPU 的設計使其能夠在大規模模型訓練中保持高效,並透過超高速網路互連減少通訊延遲,從而提高整體運算效率。
而不僅是在最新一代的 AI 晶片上,谷歌與英偉達之間的「暗戰」實際上已經存在了 8 年,從 2016 年谷歌自研 AI 晶片 TPU 就開始。
到今天,英偉達的 H100 GPU 是目前主流市場上最受歡迎的 AI 晶片,不僅提供了高達 80GB 的高頻寬內存,還支援 HBM3 內存,並透過 NVLink 互連實現多 GPU 的高效通訊。基於 Tensor Core 技術,H100 GPU 在深度學習和推理任務中具有極高的運算效率。
但同時,TPUv5e 在性價比上具有顯著優勢,特別適合中小規模模型的訓練。 TPUv5e 的優勢在於其強大的分散式運算能力和最佳化的能耗比,使其在處理大規模資料時表現出色。此外,TPUv5e 也透過Google雲端平台提供,方便使用者進行靈活的雲端訓練和部署。

谷歌資料中心,圖片/谷歌
整體來說,英偉達和Google在AI 晶片上的策略各有側重:英偉達透過提供強大的算力和廣泛的開發者支持,推動AI 模型的性能極限;而谷歌則透過高效的分散式運算架構,提升大規模AI 模型訓練的效率。這兩種不同的路徑選擇,使得它們在各自的應用領域中展現了獨特的優勢。
不過更重要的是,能打敗英偉達的,也只有採用軟硬體協同設計策略,同時擁有強大的晶片能力與軟體能力的對手。
谷歌就是這樣一個對手。
英偉達霸權的最強挑戰者
Blackwell 是繼 Hopper 之後英偉達的另一個重大升級,具有強大的運算能力,專為大規模語言模型(LLM)和生成式 AI 而設計。
據介紹,B200 GPU 採用了台積電N4P 製程製造,擁有多達2080 億個電晶體,由兩塊GPU 晶片採用互連技術「組成」,並且配備了高達192GB 的HBM3e(高頻寬記憶體),頻寬可達8TB /s。
而在效能上,Google的 Trillium TPU 相比上一代 TPU v5e 在 BF16 下提升了 4.7 倍,HBM 容量和頻寬、晶片互連頻寬也都翻了一番。此外,Trillium TPU 還配備了第三代SparseCore,可以加速訓練新一代基礎模型,延遲更低,成本也更低。
Trillium TPU 特別適合大規模語言模型和推薦系統的訓練,可以擴展出數百個集,透過每秒PB 級別的網路互連技術連接數以萬計的晶片,實現另一種層面的超級「電腦」 ,大幅提升運算效率和減少網路延遲。

圖片/谷歌
從今年下半年開始,Google Cloud 用戶就能率先採用這款晶片。
總的來說,Google TPU 的硬體優勢在於其高效能的算力和低延遲的分散式訓練架構。這使得 TPU 在大規模語言模型和推薦系統的訓練中表現出色。然而,Google TPU 的優勢還在於獨立於 CUDA 之外另一個完整的生態,以及更深度的垂直整合。
透過 Google Cloud 平台,使用者可以靈活地在雲端進行訓練和部署。這種雲端服務模式不僅減少了企業在硬體上的投入,也提高了 AI 模式的訓練效率。 Google、 Cloud 也提供了一系列支援 AI 開發的工具和服務,如 TensorFlow 和 Jupyter Notebook,讓開發者能夠更方便地進行模型訓練和測試。

蘋果用上的Google TPU v5p,圖/谷歌
谷歌的 AI 生態系統中還包含了多種開發工具和框架,如 TensorFlow,這是一個廣泛使用的開源機器學習框架,能夠充分利用 TPU 的硬體加速功能。谷歌還提供了其他支援 AI 開發的工具,如 TPU Estimator 和 Keras,這些工具的無縫整合大大簡化了開發流程。
此外,Google的優勢還在於:Google自己就是對 TPU 算力需求最大的客戶。從 YouTube 海量影片內容的處理,到 Gemini 的每一次訓練和推理,TPU 早就融入Google的業務體系之中,也滿足了Google的巨量算力需求。
可以說,Google的垂直整合遠比英偉達來得徹底,幾乎完全掌握了從模型訓練到應用,再到用戶體驗的關鍵節點,這實際上也給了谷歌更大的可能,可以根據技術和市場趨勢從底層開始優化效率。
所以儘管在晶片的性能指標上,Trillium TPU 依然難以和 Blackwell GPU 相抗衡,然而具體到大模型的訓練上,谷歌仍能透過系統性地優化效率,比肩甚至超越英偉達 CUDA 生態。
在 Google Cloud 用 TPU,是蘋果最好的選擇
簡言之,Google TPU 叢集效能、成本和生態的優勢,使其成為大規模 AI 模型訓練的理想選擇。反過來,在 Google Cloud 用 TPU 也是蘋果現階段最好的選擇。

基於 TPU v4 的超算,蘋果也用到了。圖片/谷歌
一方面是性能和成本。 TPU 在處理大規模分散式訓練任務時表現出色,提供高效、低延遲的運算能力,滿足蘋果在 AI 模型訓練中的需求。而透過使用 Google Cloud 平台,蘋果可以降低硬體成本,靈活調整運算資源,優化 AI 開發的整體成本。
另一方面是生態。谷歌的AI 開發生態系統也提供了豐富的工具和支持,使得蘋果能夠更有效率地開發和部署其AI 模型,再加上Google Cloud 的強大基礎設施和技術支援也為蘋果的AI 專案提供了堅實的保障。
今年 3 月,曾經任職於英偉達、IBM 和谷歌的 Sumit Gupta 加入了蘋果,領導雲端基礎設施。根據報導,Sumit Gupta 於 2021 年加入Google的 AI 基礎架構團隊,並最終成為了Google TPU、自研 Arm CPU 等基礎架構的產品經理。
Sumit Gupta 比蘋果內部絕大部分人都更了解Google TPU的優勢所在。
AI是一個有廣泛應用前景的工具,如果需要購買付費AI服務,一張優秀的國際虛擬信用卡是您必備的工具。牛牛平台就是專門提供國際虛擬信用卡的平台,敢興趣的朋友可以回到官網或增加客服TG(@bullbull1999)進行了解。


