
o1只是一個開始
經過漫長的等待,OpenAI終於在9月12日發布了新模型O1,用戶可以直接訪問預覽版o1-preview,或是小尺寸版o1-mini。其醞釀了快一年的大招,一會兒Q*、一會兒草莓、一會兒AGI、一會兒GPT5,耗得核心技術團隊都快走光了,才終於拿出來讓所有人檢驗和評論。這樣備受矚目的產品,勢必對產業甚至社會產生深遠的影響。而且它不像平常那些版本更新一樣,只是簡單的技術能力提升,而需要從多個視角和維度去觀察和預測其影響。
一、大進步
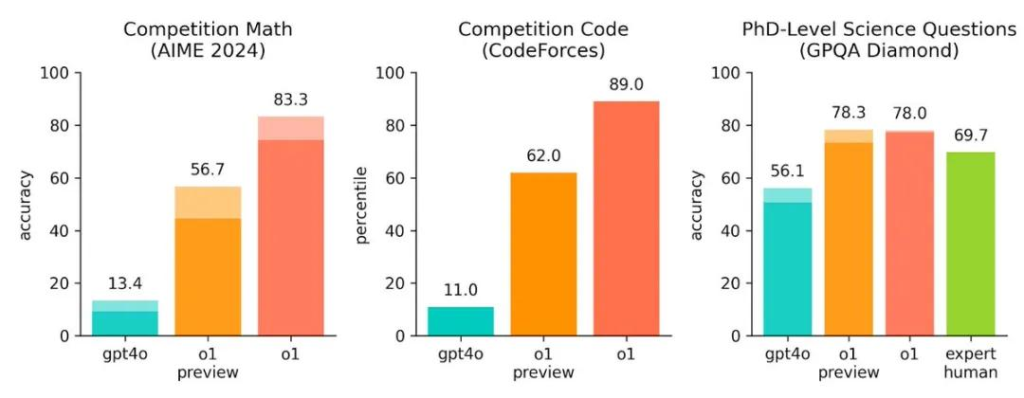
與GPT-4o相比,o1-preview在解決數學和程式設計問題上的能力提升了5倍以上,而還未放出的o1則超過8倍!在解決博士級科學題目的時的成功率,都已經超過了人類專家的水平。理化競賽能力都超過了人類博士的水平;在國際數學奧林匹克(IMO)資格考試中,GPT-4o 只正確解決了13% 的問題,而推理模型的得分為83%;編程能力在Codeforces 競賽中超過了89%的人類選手。 o1看起來在包括科學在內的各個領域都超過人類的最強能力,不難理解奧特曼之前對實現AGI的滿滿自信。
在實際操作中,可以看出新模型的推理過程與之前有很大差異。我們可以看到多了一個可以打開和關閉的Show chain of thought(顯示思路)框,顯示了整個思維過程。類似於人類在回答難題之前的長時間思考,o1 在嘗試解決問題時會透過思考將問題分解,並步步為營,反覆思考每個小任務,認識並糾正錯誤。當一個方法不起作用時,它會嘗試另一種方法,從而極大地提高了模型的推理能力。
在這些令人興奮的能力進展背後,一系列被大家長期猜測的技術進展也一一被驗證。
1、思維鏈
CoT(Chain of thought,思維鏈),是學者發現的能夠激發大模型透過「思考」來回答困難問題的技術,可以顯著提高其在推理等任務上的正確率。這個想法在兩年前的幾篇經典論文中已經不斷改進。
《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,NeurIPS2022》這篇文章提出,在問LLM問題前,手工在prompt裡面加入一些包含思維過程(Chain of thought)的問答示例(Manual CoT),就可以讓LLM在推理任務上大幅提升。

《Large language models are zero-shot reasoners. NeurIPS2022》提出先使用「Let’s think step by step.」 讓模型自己給出推理過程(Zero-shot CoT ),也衍生出諸如「一步一步慢慢來「這些著名的咒語。

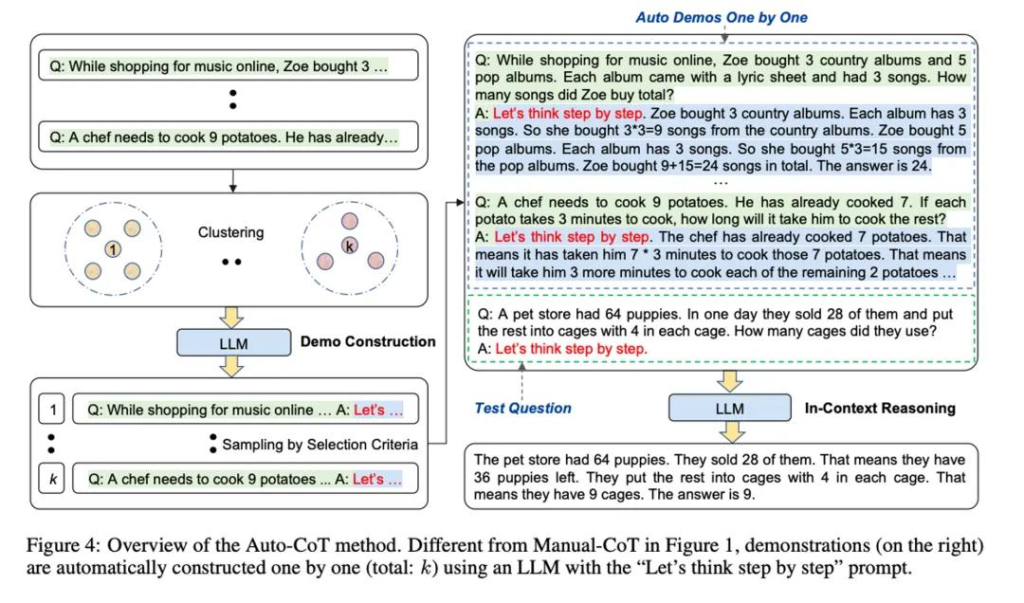
《Automatic Chain of Thought Prompting in Large Language Models,ICLR2023》這篇文章可以理解為二者的結合,先用「Let’s think step by step.」 咒語產生推理過程,再把這些過程加到prompt裡面去引導大模型推理。這樣不需要自己寫,又能相對可靠。
在這些之後,CoT還經歷了千變萬化的演進,但大都還是透過prompt來誘導大模型分步思維,人們就在想,能不能讓大模型自己學會這種方法呢?
2、強化學習與自學推理
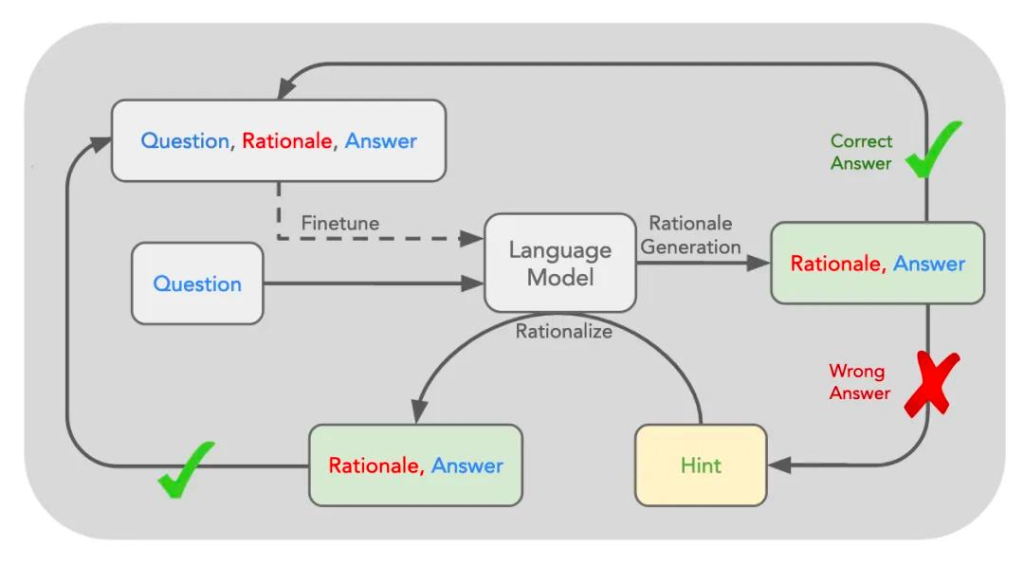
類似當年的Alpha-Zero,強化學習是讓機器自己透過與環境互動並觀察結果的方式調整行為策略的機器學習方法,但之前很難用於語言模型。直到史丹佛大學2022 年提出一種「自學推理」(Self-Taught Reasoner,STaR)方法:先給模型一些例題詳細解法,再讓模型學著去解更多的題,如果做對就把方法再補充到例題裡,形成資料集,對原模型微調,讓模型學會這些方法,這也是經典的自動產生資料的方法。
後來基於此又演進出了名為”Quiet-STaR”的新技術,也就是傳說中的Q*,翻譯過來大概為”安靜的自學推理”。核心為在每個輸入 token 之後插入一個”思考”步驟,讓大模型產生內部推理。然後,系統會評估這些推理是否有助於預測後續文本,並相應地調整模型參數。這種方法允許模型在處理各種文本時都能進行隱含的推理,而不僅僅是在回答問題時。
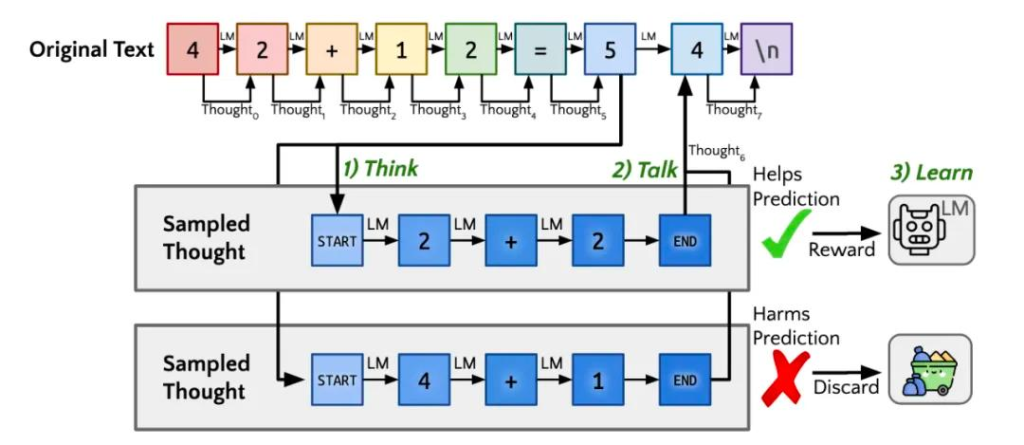
用人話說呢,加入強化學習就是在大模型訓練時就教他一些套路(當然應該也是模型自己生成並優選的),思考時直接就按題型選套路分解問題、按步驟執行、反复審核,不行就換個套路,跟通常教小學生普奧的套路類似。但這種自學習機制,由於獎勵模型的複雜,通常只在數學和程式碼領域表現較好。
3、Scaling Law的延伸
以上技術手段結合的後果就是,預訓練階段並沒有什麼變化,但在推理階段的計算量大大增加,原來追求的快思考變成了故意放慢速度,以追求更加準確的結果。
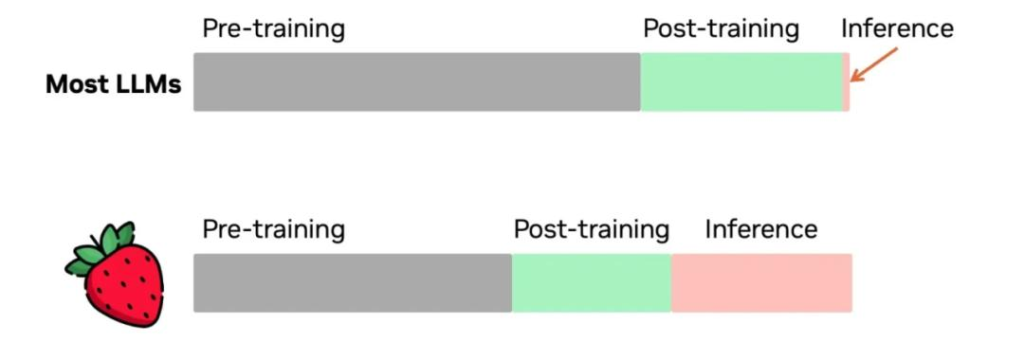
OpenAI 提及了自己訓練中發現的一個現象:隨著更多的強化學習(訓練時計算)和更多的思考時間(推理時計算),o1 的表現能持續提升。
英偉達AI領導者Jim Fan 在X 上點評了這一事件的歷史意義——模型不僅僅擁有訓練時的scaling law,還擁有推理層面的scaling law,雙曲線的共同增長,將突破之前大模型能力的提升瓶頸。 “之前,沒有人能將 AlphaGo 的成功複製到大模型上,使用更多的計算讓模型走向超人的能力。目前,我們已經翻過這一頁了。”
可以預見,在預訓練邊際成本遞減的背景下,基於強化學習的推理增強會越來越受到重視並發揮作用,也會有更多的算力被投入到推理階段,全球人工智慧晶片和算力的需求也會持續增加。
二、小技巧
不可否認,o1代表了人工智慧領域的重要進步。但細細回顧過去一年奧特曼的言行,以及OpenAI的組織架構和核心團隊的變化,不免讓人產生一些疑慮:這個故事會不會有些許誇大其詞之處?會不會是藉助一系列小技巧,來維持公司估值的成長和資源的取得呢?
1.技術壁壘
無論是Sora或o1,其實都是基於已有科研成果的工程創新,並沒有多高的技術障礙。 OpenAI最大的貢獻還是堅定而不計成本地率先實踐。跟Sora一樣,一旦OAI明確了技術方向,工程復現大機率只是時間問題,而OAI在所有方向上捲贏全球簡直是不可能的任務。況且以這幾天全網的測試情況,模型效果只能說差強人意,很多場景下還不如其他工程手段下思維鏈方法的結果(如Claude3.5),甚至可以說經常只是概率稍大的抽卡,實用價值還很難確定。另外,也許是為了避免友商的窺探和抄襲,或者是因為開放的思維過程存在安全性問題,OpenAI並未向用戶開放整個思維鏈細節,但仍有研究者在很短時間內宣稱復現了與之類似的推理能力。
可以想像,後面各大廠商都會開始卷推理,陸續推出「深思熟慮」版的模型,快速拉齊水平,而如果OpenAI後面再沒有拿得出手的底牌,仍然難以扭轉本輪模型競賽到頂的困境。
2、成本
去年已經基本完成的模型拖延了這麼久才面世,除了眾所周知的安全原因外,可能是因為o1和Sora一樣,算力消耗過於巨大而並不具備大規模商用的可行性。面對這項挑戰,奧特曼團隊一直在嘗試尋找解決方案。他們等待了很長時間,希望算力成本能隨著技術進步而下降。同時,他們也在全球四處融資,籌集資金來購買或租賃更多的運算資源。然而,即使經過了這些努力,推出的產品仍然單次推理動輒需要數分鐘甚至數十分鐘,單價高出4o數倍,token消耗也經常會提升數倍。
這些因素導致了一個尷尬的局面:科學研究貢獻暫時遠大於商業價值。在這樣的背景下,OpenAI的產業地位和估值能否維持,變得相當不確定。高昂的研發和營運成本,加上商業化受阻,可能會影響投資者的信心和市場預期。
3.方法論
如果說前面兩點商業視角的質疑對一路引領的OAI有一些不公平,那麼這個方法論是不是真的如其所說,能達到甚至超過各STEM領域的“博士水平”,其實也是值得進一步討論和驗證的。從原理上說,這種思路還是在「大力出奇蹟」的Scaling Law基礎上繼續疊加buff,引入類似蒙特卡洛樹搜索等暴力方法多路徑嘗試推理,某種意義上是在用文科方法解決理科問題。類似先前的AutoGPT類應用,面向複雜問題,如果不對思維鏈的搜尋空間進行嚴格限制和引導,可能會陷入漫無邊際的發散,消耗大量算力仍然無法得到需要的結果。
如前文提到,這種方法有些類似面向普通學生的「普奧」中常用的套路式教學,更依賴記憶和模式匹配,而並非對問題本質的深刻理解和創造性思維。就連9.11和9.8誰大都還要琢磨半天,還有相當機率答錯。這種方法培養出的AI,恐怕更像是一個只會刷題刷分的”小鎮做題家”,而非真正具有洞見和創新能力的”博士”,畢竟只有“做題”過程的訓練數據好找。
誠然,在現實中,大量的科學研究工作確實涉及重複性、機械性的任務,這部分工作如果能夠由AI來承擔,無疑會大大提高科研效率。但科學研究的核心仍在於創新,在於對未知問題的探索和新知識的發現。這需要的是靈感、創造力和邏輯推理能力,而非單純的運算能力。
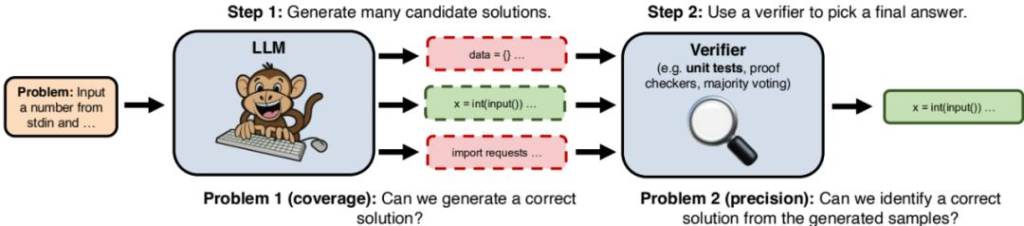
正如《Large Language Monkeys: Scaling Inference Compute》一文所指出的,僅僅通過增加生成樣本的數量來擴展推理計算,本質上並沒有改變大型語言模型的基本屬性,它仍然是一個基於統計概率進行”打字”的”猴子”。要真正實現通用人工智慧,實現科學領域的突破性進展,我們可能需要在演算法和架構上尋求更本質的創新,而不是簡單地堆砌算力。
三、新思路
前面是誇也誇了,踩也踩了,但歸根到底,筆者認為這些都並非o1的最重要價值。雖然看起來並非OAI眼中的重點,但在材料中多次提到了一個很重要的點,就是o1更適用於科學、編碼、數學和類似領域的複雜問題,或者更確切地說,是複雜問題中的繁瑣工作,尤其是多步驟歸納或演繹推理。例如,“醫療保健研究人員可以使用 o1 來註釋細胞測序數據,物理學家可以使用 o1 生成量子光學所需的複雜數學公式,所有領域的開發人員可以使用 o1 來構建和執行多步驟工作流程。”
以前我們對人工智慧的期待,往往是一個模型既有知識,又有智力,甚至還要有情感和創意,以至於模型的參數量和算力消耗不斷攀升。但也許這些目標是用各種不同的方法來解決,有些可能還是非技術方法。 o1的未來或許確實會以某種方式提升原來多模態模型的世界理解能力,但其本身的核心價值,恰恰是一個與世界知識大幅解耦的推理模型。這一點在o1-mini上體現得更加徹底,作為一個低成本的小模型,尤其擅長編程這種不需要太多世界知識的多步驟嚴謹推理場景。
人類學習的過程,是先大量學習知識,透過神經元的大量活化和連結形成智力,而具體的知識則往往會被忘記,類似張無忌學太極拳的過程。在解決不同問題過程中,除了以語言理解和邏輯推理能力為基礎,還要靠可信知識的查閱和引用,靠靈感創意的湧現,靠情感的人際連結和感應……人工智慧也不會僅僅是一個深度學習大模型,而會成為一個越來越「稀疏「而靈活的能力組合,甚至是一套人機協同的新機制。 「做題」能力肯定是必要的,但學會了做題,離解決實際問題,還有相當長的距離。
o1的出現,或許預示著這樣一個”能力稀疏化”的趨勢。未來的人工智慧,將從單一的大模型,逐漸演化為知識、推理、創意、情感等不同能力模組的靈活組合,並與人類形成更緊密和高效的協作。 o1只是一個開始,期待百花齊放的未來。
如果需要付費AI工具的朋友,可以選擇直接開立虛擬卡。牛牛Card就是一個專門提供虛擬卡的平台(可以免KYC),有興趣的朋友可以加入客服TG(@bullbull1999)諮詢了解。


