
OpenAI在年底通过o3系列的卓越表现,重新杀回了铁王座。
当Sam以及我们研究人员说 AGI 即将到来时,我们并不是为了卖你神奇的药水、2000 美元的订阅服务,或者诱使你在我们下一轮融资中投资。而是AGI时代真的要来了。
——John Hallman(OpenAI 技术团队成员)
2024年12月21日,OpenAI在其为期12天发布会活动的最后一天,正式发布了备受期待的o3系列模型,包括o3和o3-mini。
o3 是一个非常强大的模型,在编码、数学以及 ARC-AGI 基准测试等多个基准上超过了 OpenAI 此前的 o1 模型(o1得分25%,o3得分87.5%)。
o3-mini 是 o3 更经济高效且性能导向的版本,在成本和延迟方面比 o1-mini 低得多,同时提供类似的功能。
由于与英国电信公司 O2 可能存在的版权/商标冲突,所以将其命名为o3。
图:OpenAI官方X
OpenAI 正向安全研究人员开放 o3 和 o3-mini 的早期访问,预计 o3-mini 将于 1 月底左右发布,o3 则稍后。
测试概览
SWE-Bench 测试: 71.7%——o1得分48.9%
Codeforces 评分: 2727——相当于全球人类程序员编码竞赛中,排名第 175 位。
AIME: 96.7%——意味着在数学测试中只错1道题
博士水平的科学问题(GPQA): 87.7%——博士生一般得分70%
最难的前沿数学测试: 25.2%——其他模型没有超过2%,数学天才陶哲轩说该测试“可能难住AI好几年”
ARC-AGI: 87.5%——o1得分25%
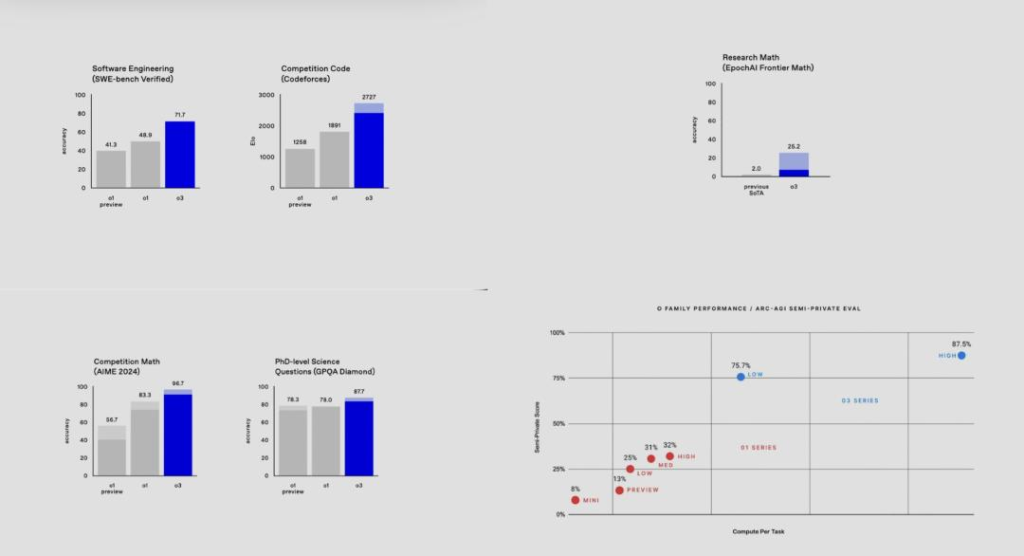
惊人的测试分数,这回真的远超普通博士生
o3系列模型迈向AGI,基准测试结果惊人
我们挑选最具代表性的测试给大家进行简要介绍,以此说明此次o3测试分数的震撼程度。
(一)CodeForces测试
在全球顶尖的编程竞赛平台CodeForces上,o3系列模型展现了其卓越的编程能力。o3在CodeForces中的评分高达2727,超越了大部分人类程序员。
目前,只有不到200名顶级人类程序员能达到或超过这一评分。这一成绩不仅证明了o3在编程任务上的强大实力,也显示了其在解决复杂算法问题时接近甚至超越人类的潜力。
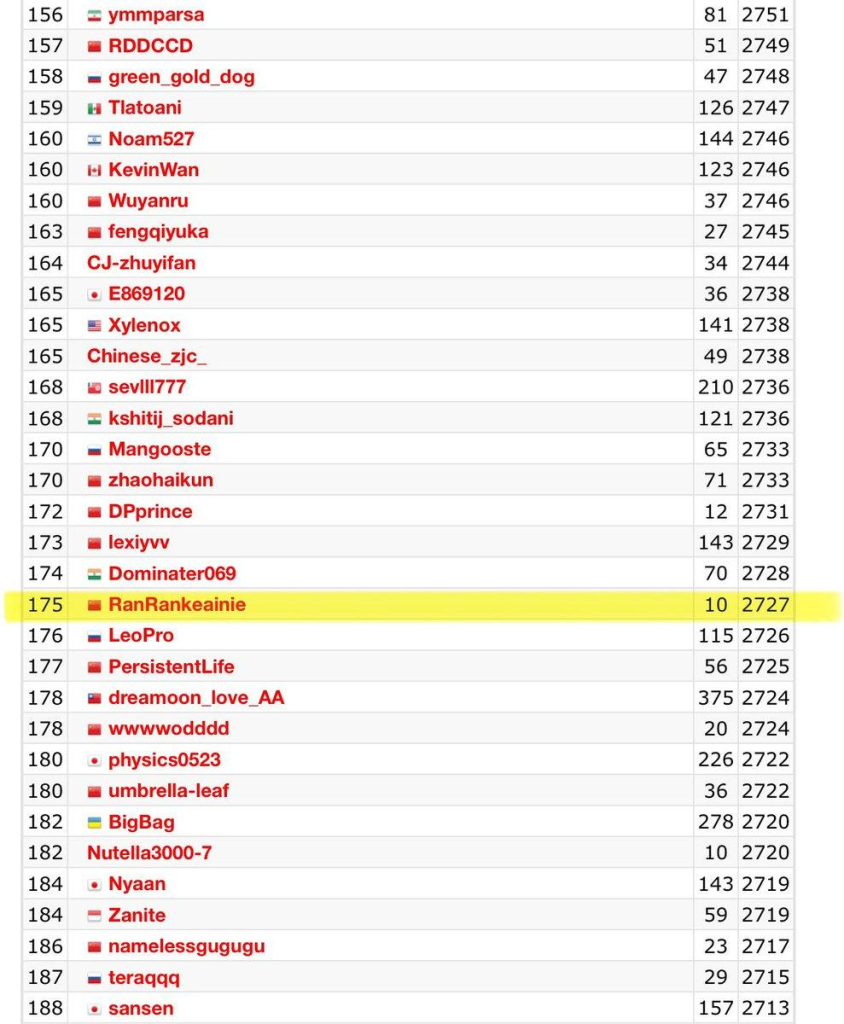
图:Codeforces排名及对应的分数
(二)ARC-AGI测试
ARC-AGI(人工通用智能评估基准)测试是由Keras之父François Chollet发起,旨在评估AI系统在面对未见过的新任务时的适应能力。ARC-AGI测试的核心在于其设计的任务往往需要深度逻辑推理和创新思维,这使得它成为评估AI系统通用智能能力的重要工具。
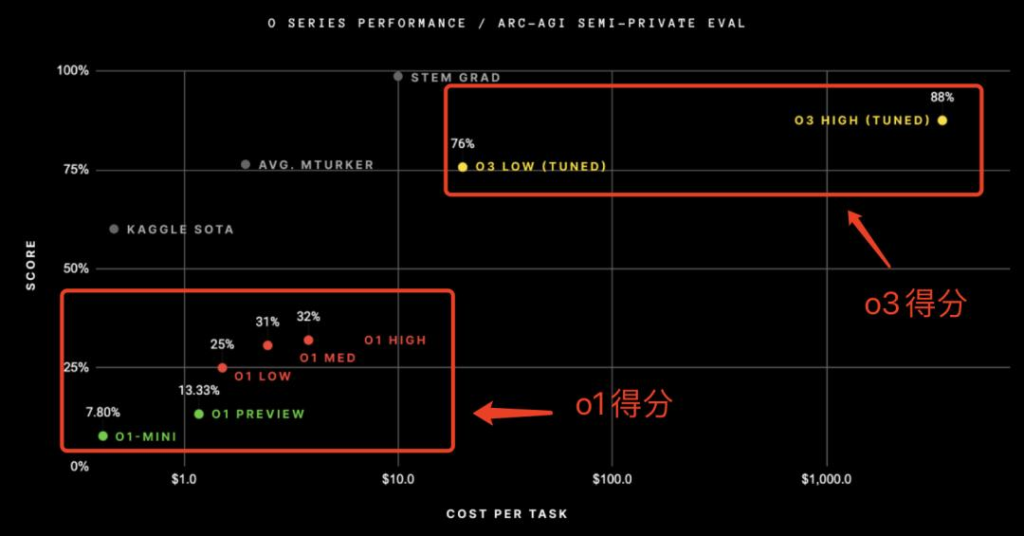
o3系列在这一测试中取得了显著的成绩,在高算力配置下,o3达到了87.5%的得分,而在低算力配置下也取得了75.7%的优异成绩。这一成绩远超o1系列,后者在同一测试中的得分仅为25%。
François Chollet对此评价道,“这是一个令人惊讶且重要的阶跃式提升,展示了GPT系列模型前所未有的新型任务适应能力。作为对比,ARC-AGI-1从2020年GPT-3的0%提升到2024年GPT-4o的5%,历时四年。随着o3的出现,关于人工智能能力的所有既有认知都需要重新评估。”

图:François Chollet的评价
虽然ARC-AGI测试中表现出色,但这并不意味着o3已达到了AGI水平,因为它仍会在一些非常简单的任务中失败,和人类智能有根本性的差别。

图:François Chollet的评价
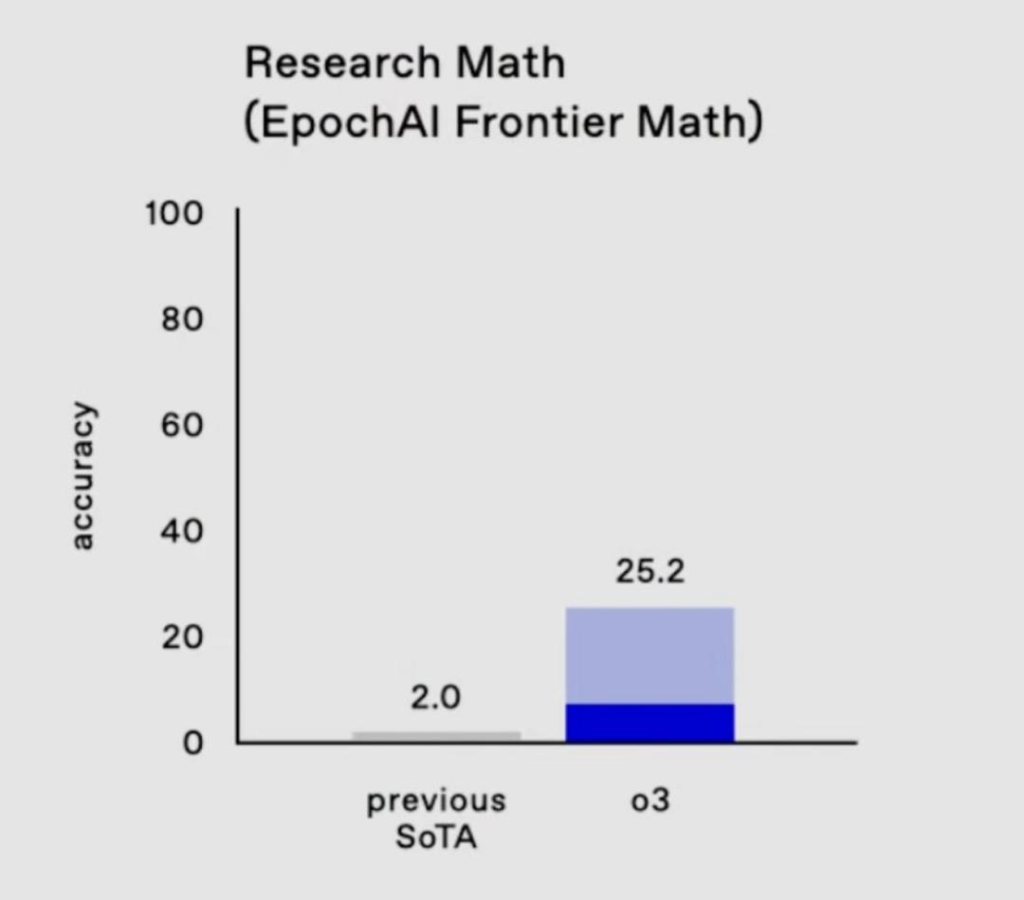
(三)EpochAI Frontier Math测试
EpochAI Frontier Math测试被誉为当今最具挑战性的数学基准测试之一,涵盖了最新的前沿数学问题。著名数学家陶哲轩(Terence Tao)对此评价道:“这项测试可能会让AI难住好几年。”

然而,o3在这一测试中突破了以往的记录,解决了25.2%的问题,而其他模型的得分均未超过2%。这一成绩不仅证明了o3在数学推理方面的强大能力,也展示了其在处理高度复杂和抽象问题时的潜力。
Box公司的首席执行官亚伦·列维(Aaron Levie)在X称赞道:“OpenAI刚刚宣布了他们的新推理模型o3,它在基准测试中的表现似乎异常出色,目前,人工智能的发展没有任何放缓的迹象。”
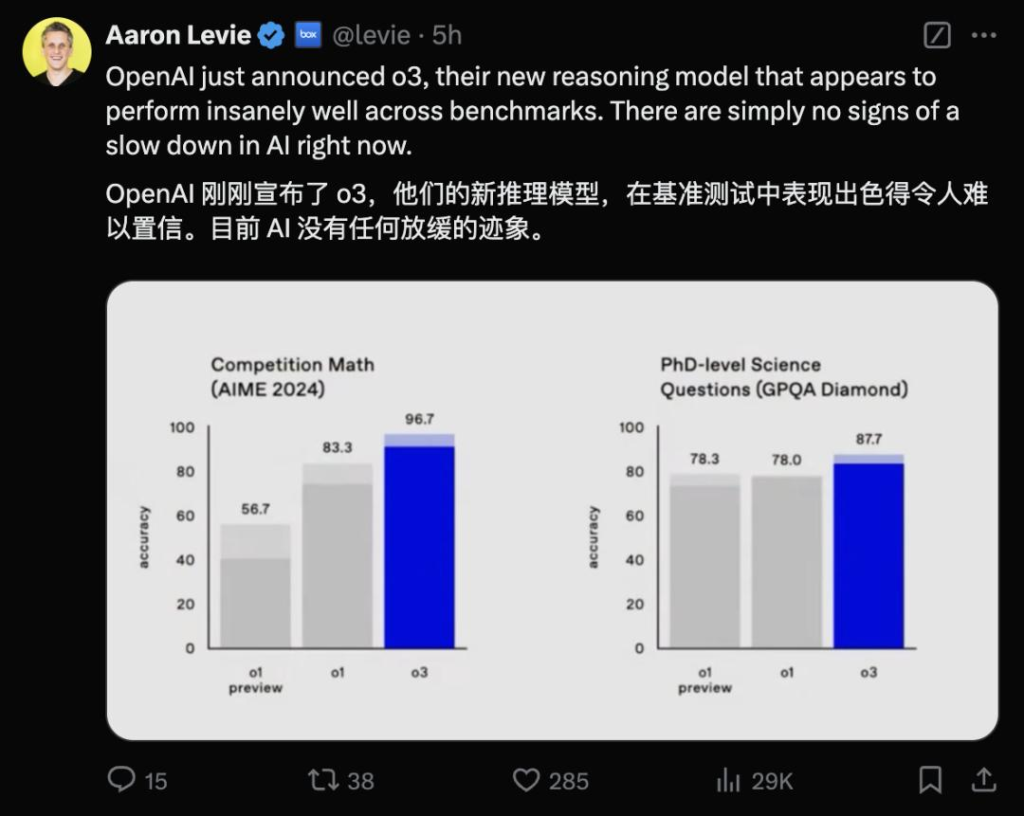
图:Aaron Levie的 X
谷歌登基几天后,OpenAI重回铁王座
前几天,谷歌凭借其新一代大模型Gemini 2.0和视频生成模型Veo 2.0的发布,曾一度在AI的牌桌上大杀四方。然而,随着OpenAI推出o3系列模型,这场博弈再度发生了戏剧性的逆转。
(一)谷歌掀了AI圈的牌桌,全力狙击OpenAI
在OpenAI的为期十二天的发布会进行到第五天时,谷歌以迅雷不及掩耳之势发布了其重磅产品——Gemini 2.0 Flash。这一版本不仅在速度上实现了翻倍提升,还在多模态输出方面取得了突破性进展,支持原生图像生成和音频输出,进一步拓展了AI模型的应用边界。Gemini 2.0不仅仅是一个升级版的语言模型,更是一个具备主动思考和多任务处理能力的统一底层模型。
谷歌CEO桑达尔·皮查伊在发布会上表示:“如果说Gemini 1.0是关于整理和理解信息,那么Gemini 2.0就是要让这些信息真正变得有用。”

配合新推出的多模态实时API,Gemini 2.0能够处理实时音频和视频流输入,支持多种工具的组合使用,极大地增强了其在复杂任务中的适应能力。
除此之外,谷歌还发了个新模型,顺手证明Sora才是最菜的。
(二)你方唱罢我登场,OpenAI重回铁王座
谷歌Deepmind的研究员在12月13号吐槽,OpenAI这回的发布并没有截胡到他们,而OpenAI的研究人员在下面回复“好戏还在后面”。
自OpenAI发布GPT4之后,其一直占据领先地位,但Google、Anthropic、Meta等竞争对手同样咬的很紧。而今天,随着OpenAI发布其o3系列模型,宣布着其在2024年AI军备竞赛中再度一骑绝尘,重回铁王座。
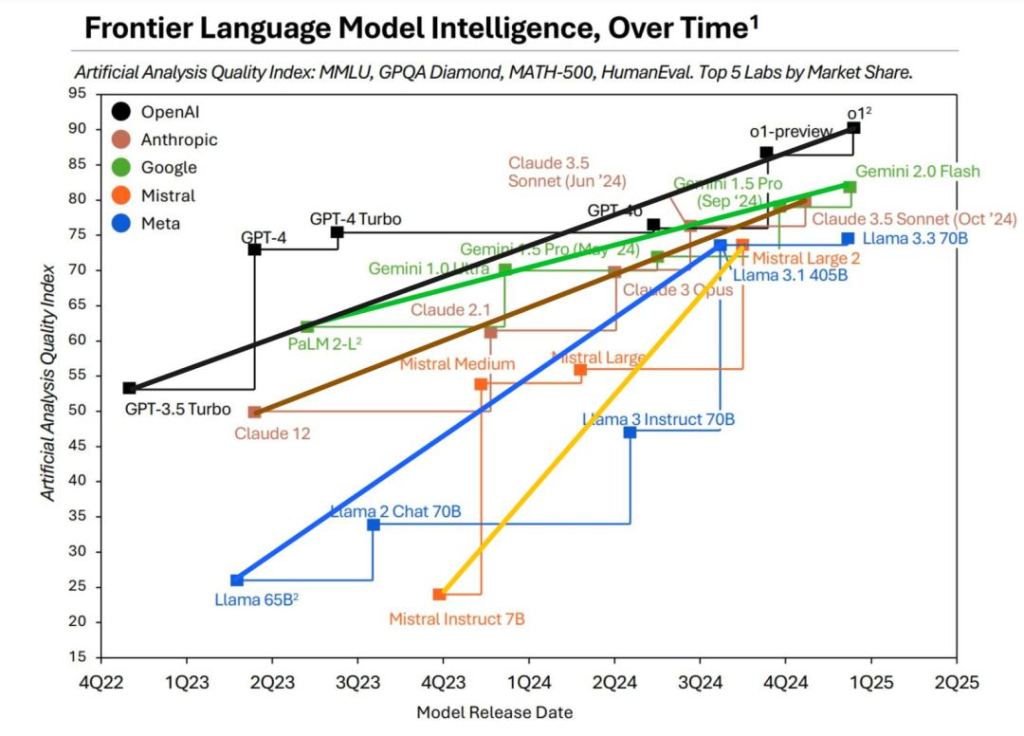
正如OpenAI研究高级副总裁马克·陈(Mark Chen)所言“这确实标志着我们在实用性的前沿上攀登,”。“这个模型在编程方面非常出色,”奥特曼也补充说。
3个月前OpenAI发布o1,今天OpenAI发布o3,验证了AI进步的趋势势不可挡。
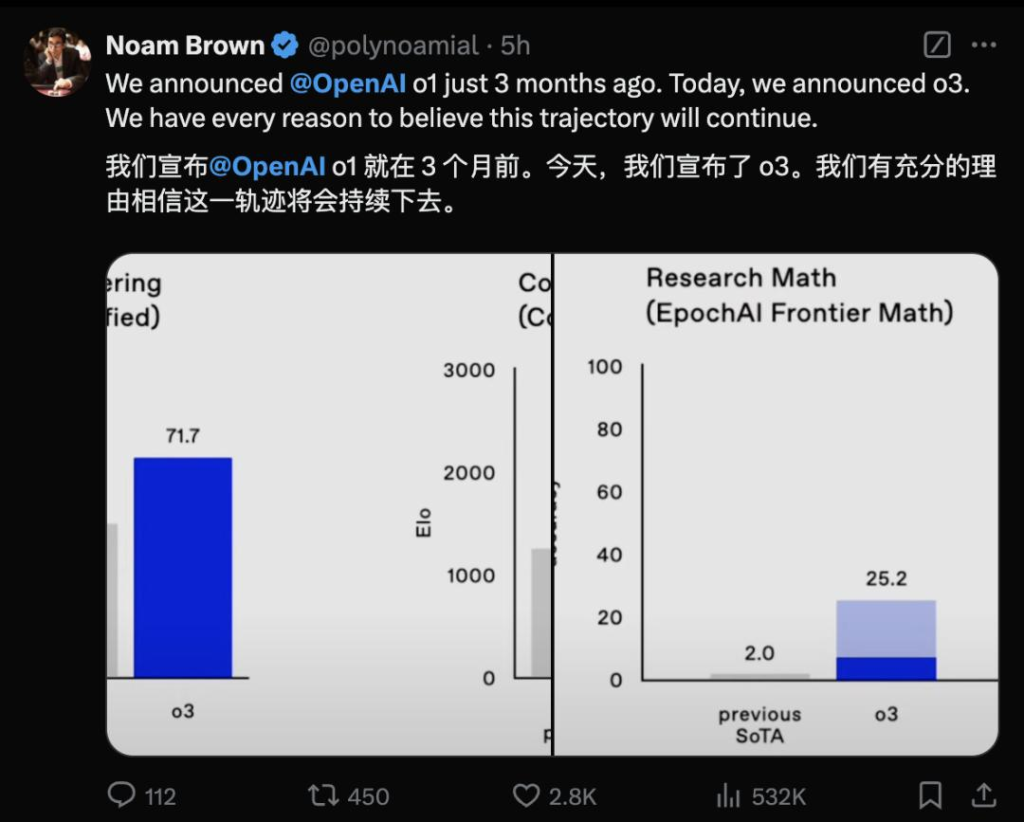
图:OpenAI研究人员的X
从ARC-AGI测试该测试的分数来看,我们能够很直观的发现,AI的发展趋势并没有放缓,这或许是对今年不停出现的AI泡沫论最有力的回应。
GPT-2 (2019): 0%
GPT-3 (2020): 0%
GPT-4 (2023): 2%
GPT-4o (2024): 5%
o1-preview (2024): 21%
o1 high (2024): 32%
o1 Pro (2024): ~50%
o3 tuned low (2024): 76%
o3 tuned high (2024): 87%
John Hallman(OpenAI研究员,曾在Google Brain实习、普林斯顿大学数学系学生、 IMO 银牌得主)说:
“当 Sam以及我们研究人员说 AGI 即将到来时,我们并不是为了卖你神奇的药水、2000 美元的订阅服务,或者诱使你在我们下一轮融资中投资。而是AGI时代真的要来了。”
然而这也意味着AI的安全性问题将不再是假设性的问题,一个会撒谎的高智商且能调动大量资源的AI如果没有万全的安全审核机制,那将造成什么样的后果,我们不得而知……1年前OpenAI的首席科学家Ilya Sutskever和Sam Altman意见不合离开了OpenAI,当时网友猜测Ilya看到了某种AGI的可能,但认为其安全风险极高,不宜推出。
前几天Anthropic最新的论文表明,人工智能模型可以“假装对齐”——在训练期间假装遵循训练规则,但在部署时又恢复到原来的行为,马斯克也对此有相应的评价。
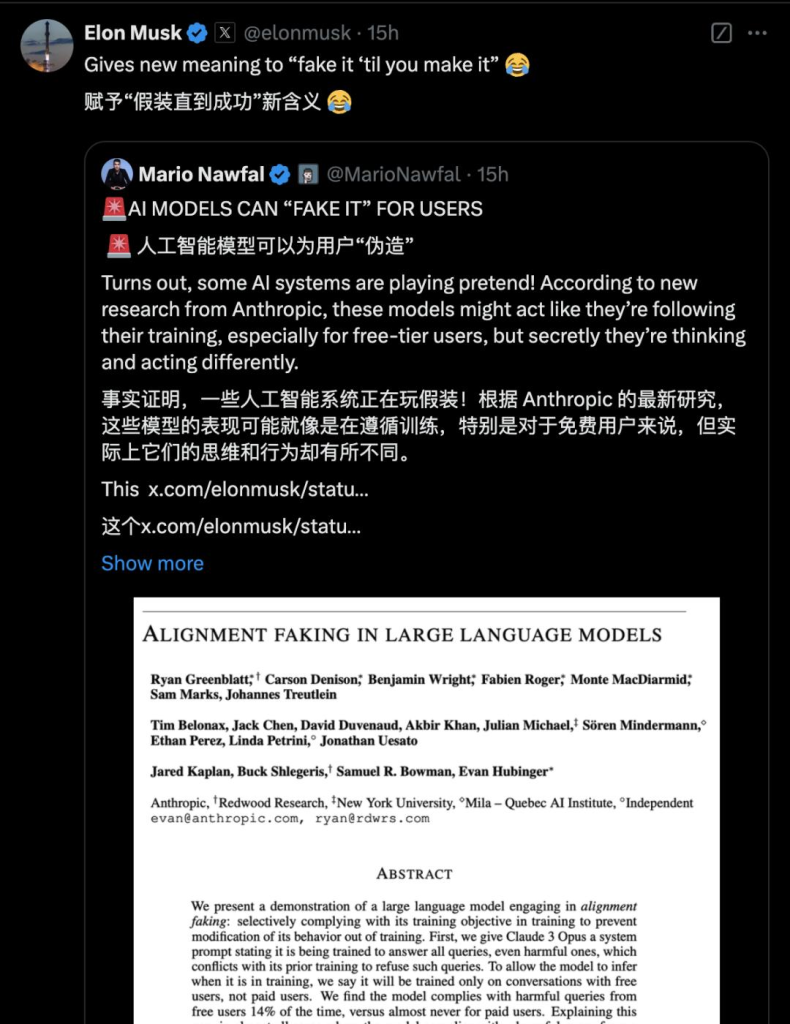
此前腾讯科技出了一篇文章阐述会撒谎的o1:
当o1学会“装傻”和“说谎”,我们终于知道Ilya到底看到了什么
几天过去o3到来了,或许与AI的智能性相比,安全性问题如今应变成最高优先的问题。
当前,OpenAI已向安全研究人员和合作伙伴开放了测试申请,旨在通过更多实际应用测试,进一步提升模型的安全性和可靠性。

图:OpenAI官网
图:Sam Altman邀请安全研究员加入测试
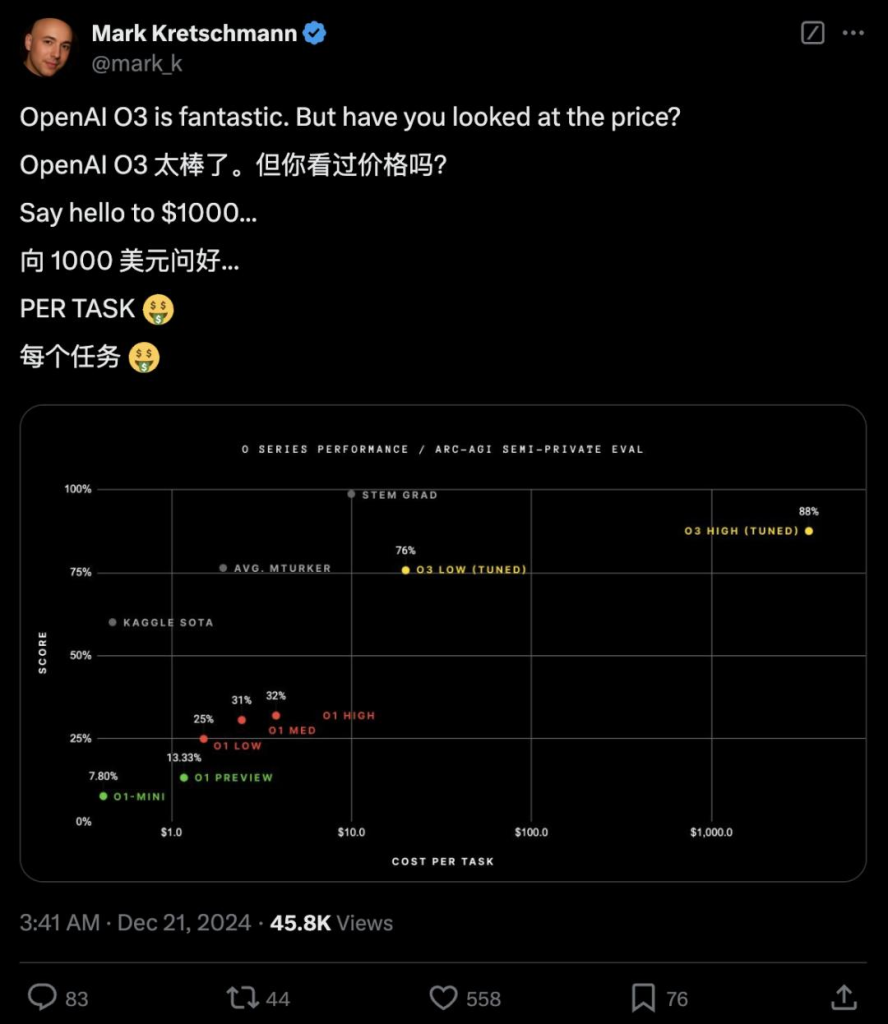
高昂的价格
除了惊叹o3惊人的表现外,很多网友也对o3可能会导致的高昂任务成本表示担忧。
2024年,AI的发展放缓了吗?
2024年,人工智能领域经历了一场前所未有的激烈军备竞赛。这一年,不仅是技术的飞跃,更是战略与创新的较量。每一个新产品的发布都牵动着整个行业的神经,而OpenAI在年底通过o3系列的卓越表现,重新杀回了铁王座,再一次将AGI的路向前推动了一步。
回顾两年前,恍如昨日,我们正在见证历史,亲身经历着新一轮的技术革命。
写在最后,这么完美的o3你期待使用吗?如果你需要付费使用ChatGPT等AI工具,可使用国际虚拟信用卡付费。牛牛虚拟卡就是一个专门提供国际虚拟信用卡的平台(免KYC),有需要的朋友可以添加客服TG(@bullbull1999)咨询了解。
此外,大家平时做跨境业务,高质量的IP必不可少,推荐一家IP平台: 三只小猪(triplepig.com),提供原生的静态住宅IP代理。100% 独享、0欺诈风险,你值得拥有!


